"In theory, there is no difference between theory and practice. In practice, there is."
58 questions. 3 document types. Same LLM. Same machine.
We've been told for years that the only way to build RAG (Retrieval-Augmented Generation) is to chunk text, embed it into vectors, and perform semantic search. But a new challenger, PageIndex, claims we can ditch the vectors entirely and use LLM-driven "navigation" instead.
I wanted to know if the hype was real. So I built both systems and put them head-to-head on the most difficult documents I could find.
The Great RAG Debate: Why Document Type Matters
Most RAG comparisons pick a single document and call it a day. That's a mistake.
A financial 10-K and a Wikipedia article are both "documents," but they are worlds apart. One has a rigid, predictable structure — a Table of Contents, numbered sections, and standardised terminology. The other is flowing prose with no roadmap, hundreds of subsections, and conversational language.
If a RAG system claims to be "the next generation," it shouldn't just work on a curated benchmark. It should work on the messy reality of diverse document types.
I tested both systems across three fundamentally different structures:
- Financial 10-Ks: Rigidly structured, long, accounting-heavy.
- Research Papers: Semi-structured, technical, dense language.
- Wikipedia Articles: Unstructured, long, conversational prose.
The Contenders: Hierarchical Trees vs. Flat Embeddings
1. PageIndex (Vectorless RAG)
VectifyAI's approach is bold: no embeddings, no vector database. Instead, an LLM builds a hierarchical Table of Contents (ToC) tree of the document at ingestion time. At query time, another LLM "reasons" over the tree to find the relevant page range. It’s like a librarian who has memorized the index of every book in the building.
2. Naive RAG (The Standard)
The classic pattern we all know: all-MiniLM-L6-v2 embeddings and a FAISS index. Every page is converted into a vector. At query time, we search for the top-3 most similar pages. It’s like a search engine looking for keywords and concepts.
The Setup: Both systems used llama-3.3-70b-versatile via Groq for final answer generation. Temperature set to 0. No special prompt engineering for either side.
Phase 1: The SEC Filings (FinanceBench)
28 questions · 15 PDFs
These are the documents PageIndex was born for. They are long, boring, and highly structured.
| Metric | PageIndex | Naive RAG |
|---|---|---|
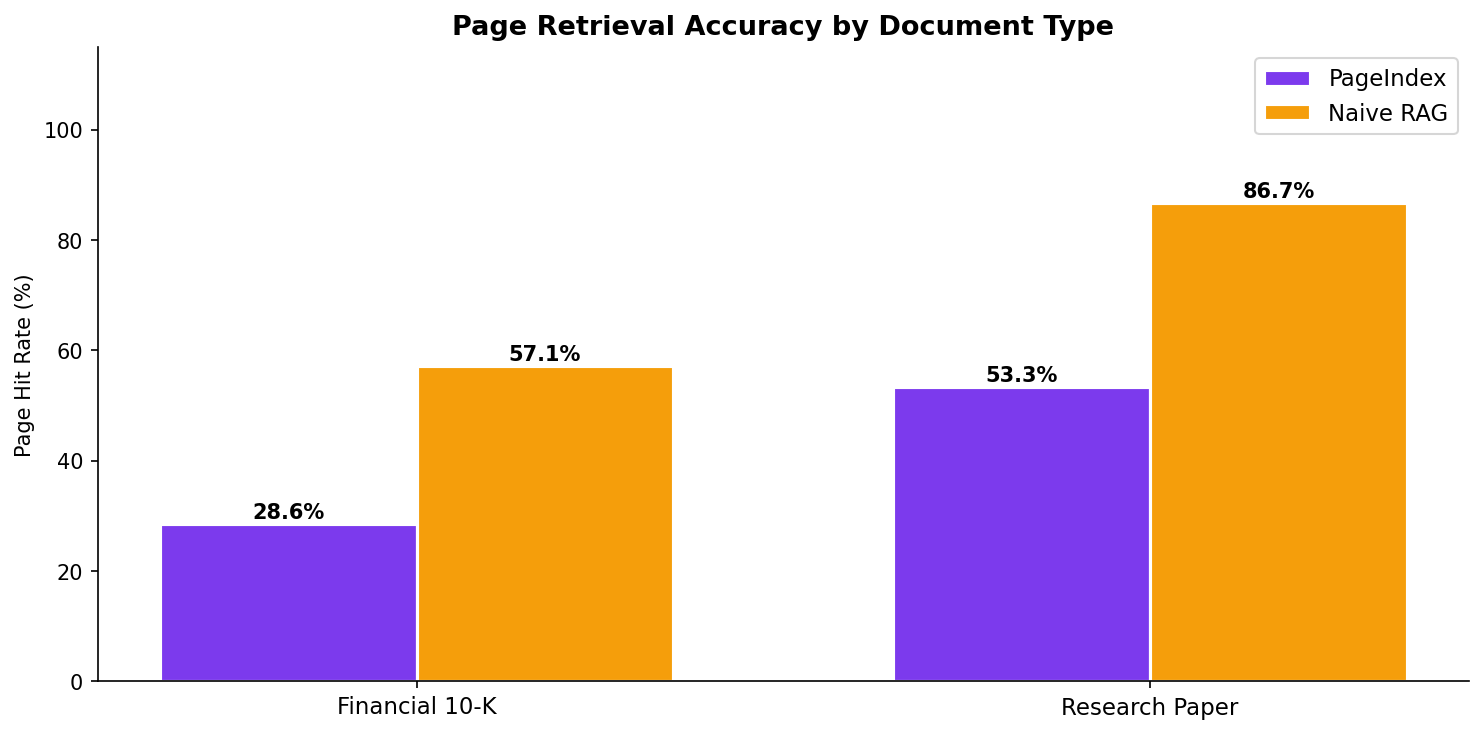
| Page Retrieval (±2 pages) | 28.6% (8/28) | 57.1% (16/28) |
| Answer Accuracy | 42.9% (12/28) | 50.0% (14/28) |
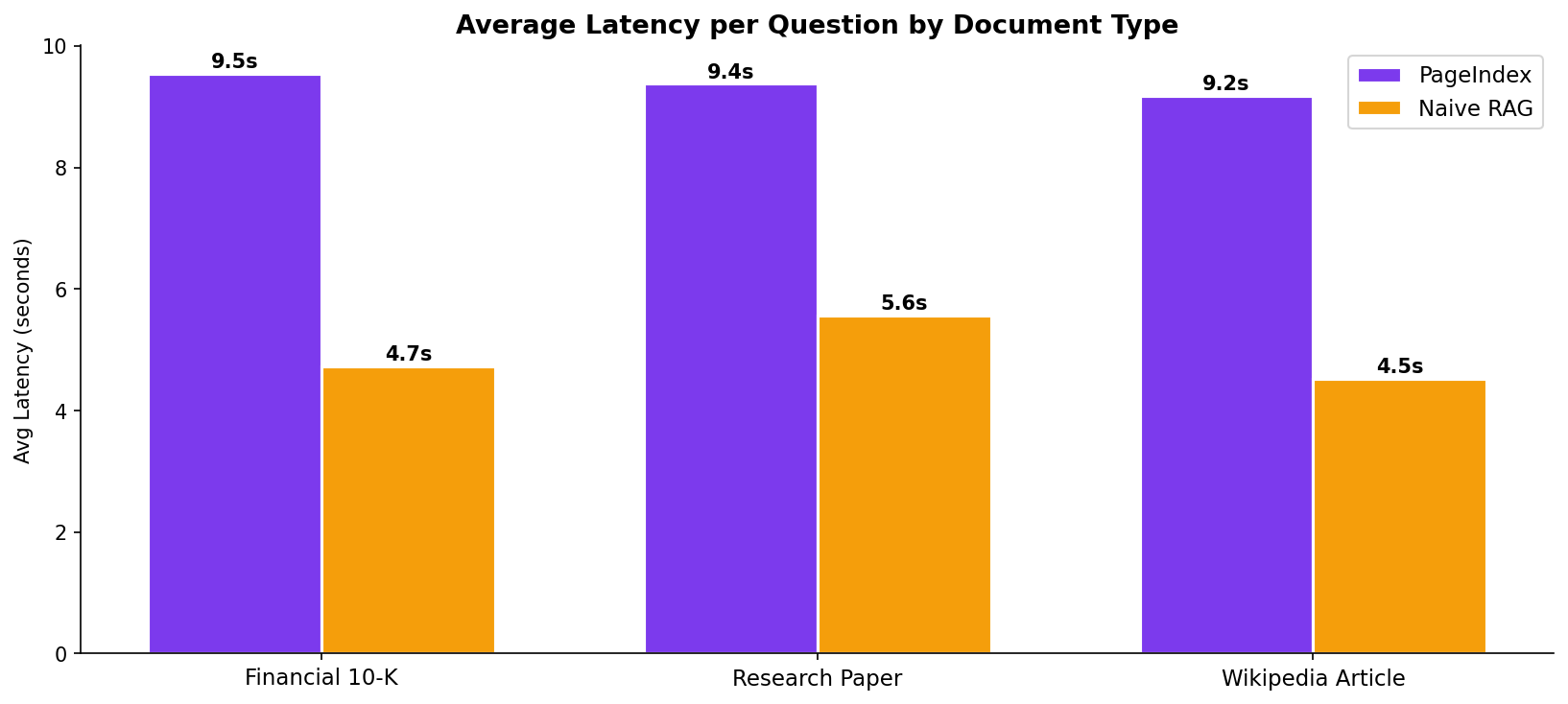
| Avg Latency | 9.5s | 4.7s |
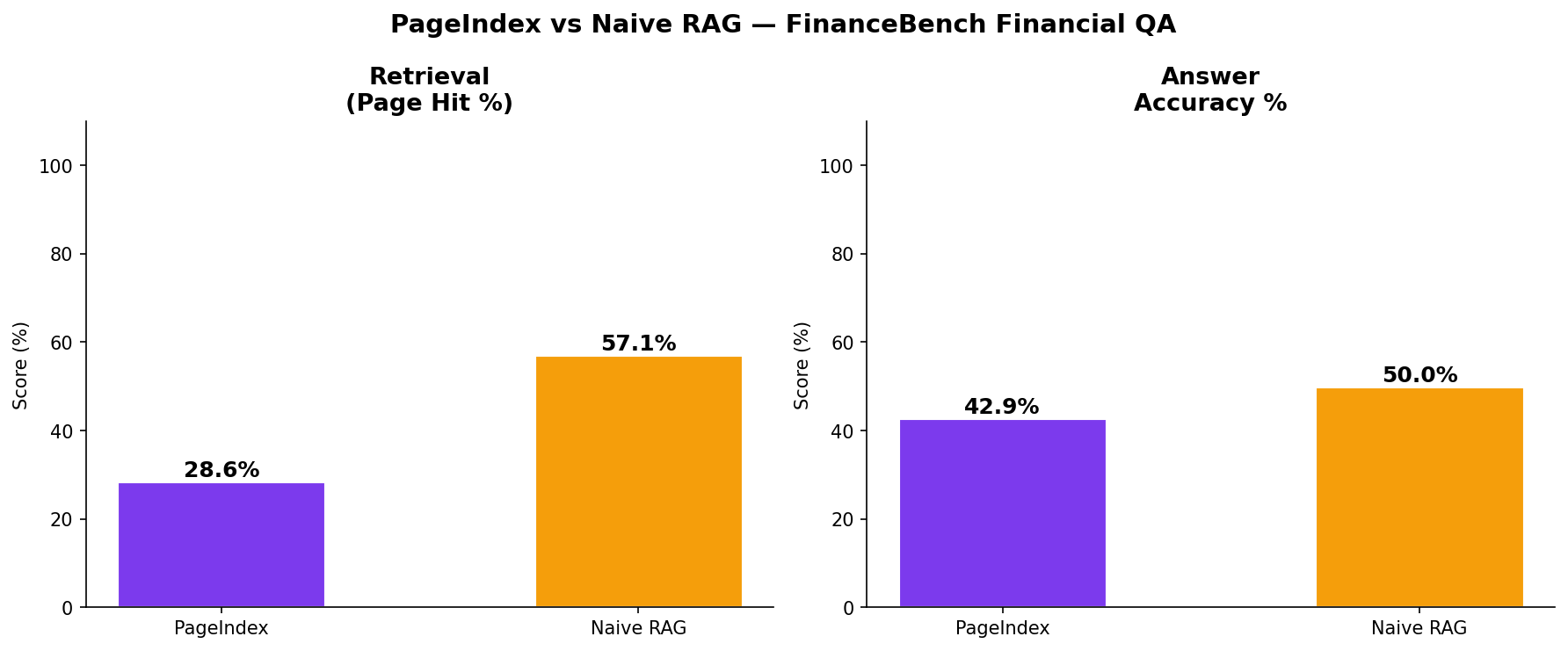
The Surprise: Naive RAG won on PageIndex's home turf. It nearly doubled the page retrieval rate and beat it on final answer accuracy. Why? Because while PageIndex was "reasoning" about where the answer should be, semantic search was just finding where the keywords actually were.
Phase 2: ArXiv Papers (Technical Density)
15 questions · 3 papers
We tested legends like Attention Is All You Need and ResNet. These papers have clear sections (Abstract, Methods, Results), but they are much shorter than 10-Ks.
| Metric | PageIndex | Naive RAG |
|---|---|---|
| Page Retrieval (±2 pages) | 53.3% (8/15) | 86.7% (13/15) |
| Answer Accuracy | 33.3% (5/15) | 40.0% (6/15) |
Naive RAG wins again. But the page retrieval numbers tell a deeper story. Naive RAG hit the right page 86% of the time, while PageIndex struggled at 53%.
Phase 3: Wikipedia (The Unstructured Stress Test)
15 questions · 3 articles
This is where the wheels fell off. Wikipedia articles on Climate Change and Machine Learning are long and have nested headers, but they don't follow a rigid template.
| Metric | PageIndex | Naive RAG |
|---|---|---|
| Answer Accuracy | 13.3% (2/15) | 40.0% (6/15) |
| Avg Latency | 9.2s | 4.5s |
PageIndex collapsed. It only got 2 out of 15 questions right. Naive RAG maintained its 40% baseline.
The Verdict: The Numbers Don't Lie
When we aggregate everything, the pattern is undeniable.
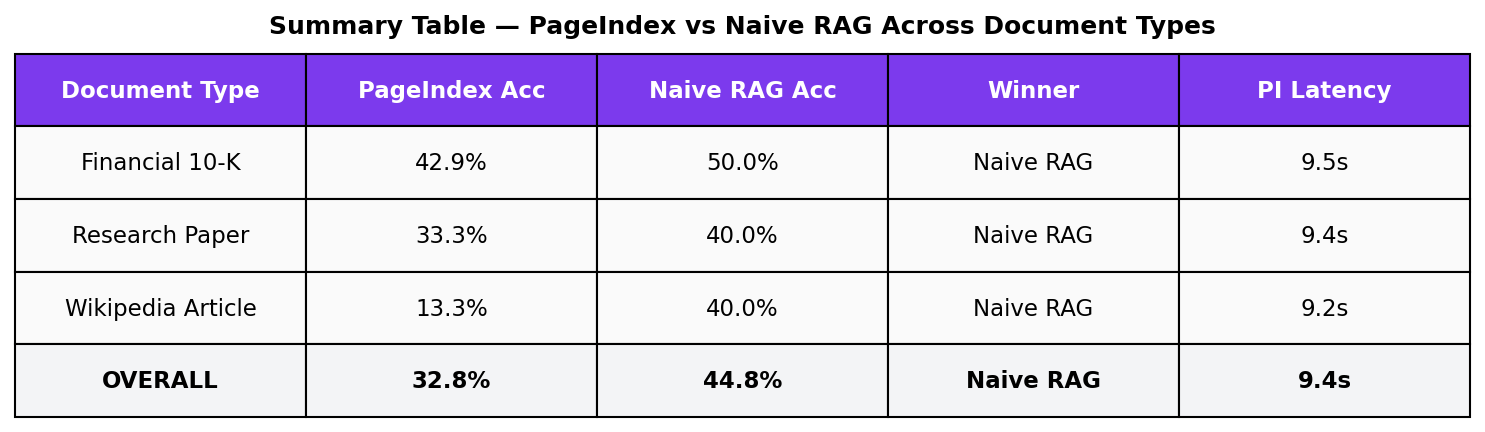
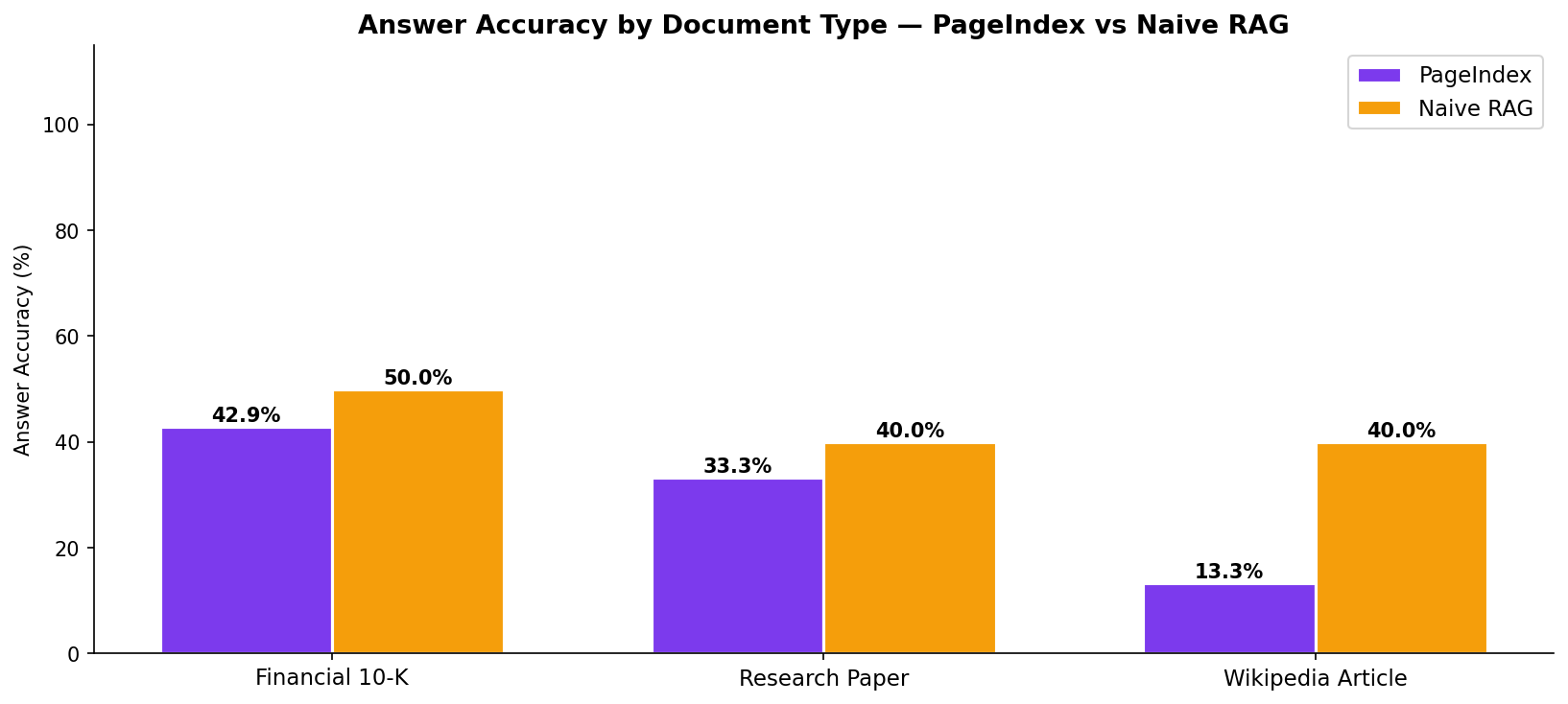
| Financial 10-K | Research Paper | Wikipedia | Overall | |
|---|---|---|---|---|
| PageIndex | 42.9% | 33.3% | 13.3% | 32.8% |
| Naive RAG | 50.0% | 40.0% | 40.0% | 44.8% |
| The Gap | +7.1pp | +6.7pp | +26.7pp | +12.0pp |
Crucial Observations from the Trenches
1. Navigation vs. Extraction
This was the most fascinating finding. In research papers, PageIndex found the right "neighborhood" (section) 53% of the time, but only translated that into a correct answer 33% of the time.
It turns out that retrieving an 8-page range of text and asking an LLM to find a needle in that haystack is hard. Naive RAG retrieves exactly 3 specific pages. Smaller haystack, easier needle.
2. The Fragility of Structure
PageIndex depends entirely on the quality of the "Tree" it builds. If a document has a clear Table of Contents (like a 10-K), it’s competitive. If the document is a long, flowing Wikipedia article, the tree-building fails, and the entire architecture collapses.
3. The Latency Tax
PageIndex requires two LLM calls: one to reason over the tree and one to generate the answer. This makes it 2x slower than Naive RAG, which only needs one LLM call after a local vector search.
4. The PDF Problem
Both systems failed miserably on tables. Why? Because PDF rendering destroys table structure. A balance sheet becomes a soup of numbers. This isn't a RAG problem; it's a data extraction problem.
When Should You Actually Use PageIndex?
Despite the lower scores, PageIndex has one superpower: Explainability.
When PageIndex answers, it tells you its "thought process":
"I'm looking in the Methods section (pages 5-8) because the user asked about training hyperparameters."
Naive RAG just hands you three chunks of text and says, "Trust me." For legal or financial compliance where you need an audit trail, that reasoning step is worth the 7% drop in accuracy.
What I'd Build in Production
The future isn't Vector vs. Vectorless. It's Hybrid.
My takeaway from this experiment is that we shouldn't hardcode our retrieval strategy. Instead, we should classify documents at ingestion:
- Is it highly structured with a ToC? Use PageIndex-style reasoning for explainable navigation.
- Is it unstructured or short? Use Naive RAG for speed and precision.
- Does it have tables? Don't even start until you've converted those PDFs to Markdown or JSON.
This is part of my technical deep-dive series. If you found this useful, let's connect on LinkedIn or follow my work on GitHub.
© Vyshakh · 2026